
La méthode CRISP, développée par IBM dans les années 60, est devenue un pilier fondamental dans le domaine de la data science. Conformément à l’évolution technologique, son approche structurée reste primordiale en 2025 pour garantir la réussite des projets d’analyse de données. Cette méthodologie est non seulement adaptable aux différents contextes d’usage, mais elle est aussi pertinente face aux défis contemporains en Big Data et en intelligence artificielle.
Les fondements de la méthode CRISP-DM
La méthode CRISP-DM, acronyme de Cross-Industry Standard Process for Data Mining, se compose de six étapes clés qui orientent le processus d’analyse des données. Chaque phase est conçue pour se construire sur la précédente, offrant ainsi une structure flexible pour réaliser des projets complexes de data science.
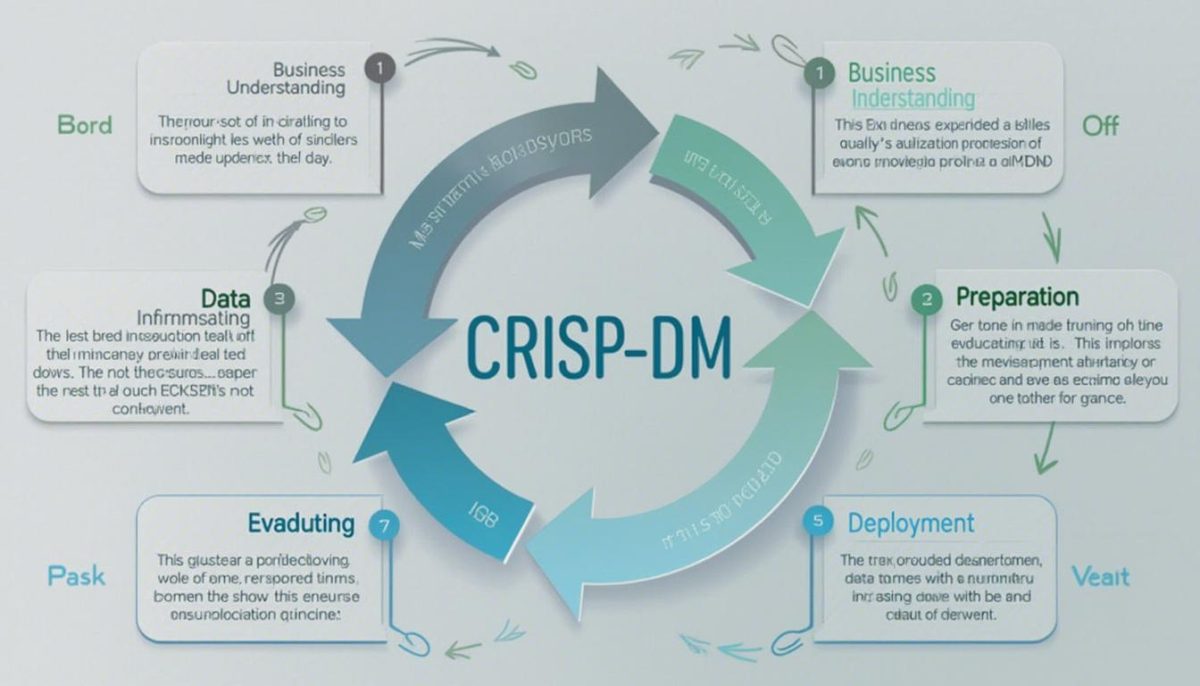
Les six étapes de la méthode CRISP-DM
- Compréhension du problème métier
- Compréhension des données
- Préparation des données
- Modélisation
- Évaluation
- Déploiement
Cette méthodologie fait la part belle à l’interaction entre les équipes techniques et métiers, garantissant que les besoins spécifiques sont pris en compte à chaque étape. Ainsi, elle favorise la collaboration indispensable pour obtenir des résultats probants.
La première étape : Compréhension du problème métier
Avant toute chose, il faut définir avec précision le problème à résoudre. Les data scientists vont collaborer étroitement avec les parties prenantes pour établir des objectifs clairs.
- Identifier les enjeux spécifiques
- Définir les succès attendus
- Établir les contraintes et ressources disponibles
Cette phase d’immersion permet de s’aligner sur les attentes des utilisateurs finaux et d’éviter les dérives durant le projet.
Compréhension des données : la base de la data science
Cette étape consiste à analyser les données disponibles pour déterminer leur qualité et leur pertinence. L’objectif est de faire le lien entre les données et les problématiques métier.
| Critères de données | Actions | Résultats attendus |
|---|---|---|
| Qualité | Évaluation des données | Détection des anomalies |
| Quantité | Analyse de l’étendue des données | Identification des vérités non explorées |
| Source | Vérification des sources de données | Confiance accrue dans les données |
Préparation des données : le Data Hub
La phase de préparation des données est essentielle. Elle implique le traitement, le nettoyage et la structuration des données pour les rendre exploitables. Le Data Hub est le point de convergence où toutes ces données sont centralisées.
- Classification des données brutes
- Élimination des incohérences
- Recodage pour compatibilité algorithmique
Cette préparation minutieuse est cruciale pour garantir que les résultats des algorithmes soient fiables et interprétables.
Modélisation : le cœur de l’analyse
La modélisation fait appel à divers algorithmes pour découvrir des patterns et réaliser des prédictions. Les outils tels que Microsoft Azure, Google Cloud, ou des plateformes comme RapidMiner et DataRobot facilitent cette étape.
- Choix des algorithmes
- Optimisation des paramètres
- Test de robustesse des modèles
Chaque modèle testé doit répondre aux objectifs initiaux définis pour évaluer son efficacité et son applicabilité.
Évaluation et déploiement : validation et mise en œuvre
Une fois modélisé, le processus d’évaluation déterminera si le modèle atteint les objectifs prédéfinis. Des outils comme SAS et Tableau sont souvent utilisés pour visualiser les résultats.
| Étape | Objectif | Critères de succès |
|---|---|---|
| Évaluation | Vérifier la précision | Résultats proches des attentes |
| Déploiement | Mise en production | Utilisation en situation réelle |
Une méthode itérative et agile
La méthode CRISP est à la fois agile et itérative. Chaque itération permet d’affiner le projet, d’approfondir la compréhension métier et d’améliorer les résultats. Ce modèle a été adopté par de nombreuses entreprises, dont Orange Business, pour sa capacité à s’adapter aux diverses exigences des projets data.
En somme, la méthode CRISP s’impose comme un cadre flexible et robuste pour réussir en data science, et ce, peu importe les outils utilisés tels que TIBCO, KNIME ou Alteryx.